Learning Type Inference for Enhanced Dataflow Analysis
Creating an LLM to infer types from Java-/TypeScript code to enhance downstream static program analysis
--
Lukas Seidel¹ ³, Sedick David Baker Effendi² ⁴, Xavier Pinho¹, Konrad Rieck³, Brink van der Merwe², and Fabian Yamaguchi¹ ²
¹ QwietAI, USA
² Stellenbosch University, South Africa
³ Technische Universität Berlin, Germany
⁴ Whirly Labs, South Africa
We improve on the current state-of-the-art for neural type inference by 7.85% (pp) by training an LLM base (CodeT5+) to predict type annotations for JavaScript code. Our model, CodeTIDAL5, achieves 71.27% overall accuracy on a challenging real-world dataset.
During our evaluation, we manually inspect the results of our type inference by analyzing slices from 10 open-source libraries and confirm that the performance follows that of the results from the dataset. We optimize and package our system as an open-source, plug-and-playable static analysis system able to run on your laptop, available on GitHub.
This article is a summary of our work published at ESORICS’23.
Introduction
Static program analysis for dynamic languages such as JavaScript and Python is notoriously difficult, especially for partial program analysis when not all external dependencies (i.e., third-party libraries) are visible or excluded for performance reasons. While statically typed languages suffer from similar shortfalls when reasoning the types of return values of calls to hidden methods, or types of members from hidden type declarations, type annotations are usually enforced and thus available to us before the program is executed.
This type information is relevant for a number of downstream tasks in program analysis, and the more type information available, the more precise and potentially performant the analysis. As an example: when performing an analysis such as taint analysis, e.g. tracking some attacker-controlled data potentially flowing to some sensitive command, we may need to tag what data we deem attacker controlled and a sensitive command.
Our running example in the paper describes an HTTP handler for some Node.js server. For tagging a source, one may choose to match certain common code patterns such as function($SOURCE, res), but a more precise way of doing this is by matching types and AST node, e.g. a parameter of type NextApiRequest, but the latter detail requires type information.
From a human perspective, it is sometimes trivial to infer the type of some given variable or understand its semantics in a snippet of source code, but for an automated analysis, it may require more information, such as the variable definition or type declaration, to make a precise inference. This is not always the case, however, and in languages such as JavaScript a developer may choose to name a variable in a way that relates to the data it represents to make the code easier to follow. Following our example, it is common to name an HTTP request variable as either req or request.
This is the motivating intuition behind the initial efforts behind using (deep) neural networks for type inference, or neural type inference, but we’ve identified the following shortcomings in these efforts.
- Limited performance on user-defined types: User-defined types in the scope of this research are any types not bundled with the standard library, e.g. ECMA, or are not primitives. Around the time of submitting our work, DiverseTyper by Kevin Jesse et al. had been released as an effort to address this challenge.
- High-effort setups: Deep neural networks often require either special hardware or some other complex setup. Program analysis tools are more likely to be adopted if they are plug-and-play.
- No integration with existing platforms: Along a similar concern of user adoption, if the tool is not conveniently packaged it is unlikely to be used. In terms of IDE support, FlexType was published late 2022 showing the integration of a GraphCodeBert type inference model into VSCode. There is no model that we have found packaged with a static analysis tool supporting a data-flow analysis pipeline.
Following the above, we propose a CodeT5+ model for Type Inference for enhanced Dataflow Analysis via Language modeling, CodeTIDAL5. Our model achieves inference scores above the current state-of-the-art, and in this blog we summarize the design, results, and provide a grounded conclusion.
Design
The following section outlines our integration into an open-source static analysis platform, as well as the architecture of our CodeTIDAL5 model.
Implementation Target
Our standard static analysis research and development mainly focuses around the open-source Joern static analysis platform. It is designed to be language agnostic, support partial program analysis, and a variety of downstream analysis including data-flow analysis. Given that it supports partial programs, i.e. code snippets or programs without dependencies, Joern is useful for tasks such as code mining, where the code is not guaranteed to compile or fetch all the dependencies, or fine-grained feature extraction, where only necessary procedures are loaded in to generate feature vectors from.
The intermediate code representation (IR) on which code is analyzed is a graph called the code property graph (CPG). Joern can be seen as the de facto implementation of this schema, given it was the original artifact of Modeling and Discovering Vulnerabilities with Code Property Graphs and is maintained with a team of contributors led by the original author.
Code Property Graph Usage Slicing
In order to identify targets for our analysis to infer, as well as present the problem in a machine-readable format, we use a technique we call CPG usage slicing. The goal of this slicing technique is to extract meaningful information about how an object interacts within a procedure. This is similar to TypeT5’s usage graph, however we omit “potential usages”, remain intraprocedurally bound while including variables captured by closures.
If call graph and type information is available, it is included, but the goal is to remain robust to this information missing. The complete input is the source code of the procedure, paired with the usage slices for each variable. Given that CodeT5+ is identifier aware, the usage slices allow us to focus the model’s attention on the correct variables and call sites in the source code during the inference task.
In order to illustrate this idea, we present a running example of a generic HTTP request handler performing a query to a DynamoDB instance. A flow exists from req over params into query().
const db = require("db.js");
const documentClient = db.documentClient;
const handler = (req, res) => {
const params = req.body.params;
documentClient.query(params, function(err, data) {
if (err) console.log(err);
else console.log(data);
});
};
export default handler;As is, without type information, this snippet alone would present usage slices where every variable is annotated with any. During training, however, we use TypeScript repositories which are often annotated with types and present in our CPG. For a human reviewer, it may be obvious by the usage and context of each variable what types they may be, e.g. documentClient may be an AWS.DynamoDB.DocumentClient or req may be __ecma.Request or NextApiRequest depending on the underlying REST framework.
At times, these variables may be documented as being of type object, but this is not so useful since most classes can be abstracted to their object version. The slice for documentClient may look something like:
{
"tgt": ["documentClient", "DocumentClient"],
"def": ["db.documentClient", "require(\"db.js\")"],
"calls": [{"name": "query", "index": 0}]
}The usage slice along doesn’t give much information, and early iterations of this work which attempted to infer types based on the usage slice alone did not perform well. However, the context given by the source code paired with the usage slice appeared to have boosted the performance of our model over related work.
Machine Learning Model
Conceptually, our model is meant to learn from (linguistic) semantic relationships, e.g., variable naming conventions and class names. As we deliberately aim to deduce clues on an object’s type from the semantic principles of how developers name variables or a class’ methods, we opt for an encoder-decoder Transformer model for contextual text processing and generation.
Architecture
The proposed model, hereinafter referred to as CodeTIDAL5 is based on Saleforce’s CodeT5+ models. In an effort to make our model portable and run alongside a static analysis task, we make use of the smallest in the family, with 220M trainable parameters, and implement various optimizations and best practices. One such optimization is using FlashAttention, that introduces substantial speedups and memory reductions to Transformers.
One motivation for selecting CodeT5+ is that it achieves state-of-the-art results on programming tasks such as natural language code search, in which a model needs to find the most semantically related code from a natural description. Given the intuition behind our thinking behind “it may be trivial for a developer to reason about the types used in a snippet of code”, the ability for CodeT5+ to understand the language used by certain code tokens and their relationships to their types motivates itself in our use-case.
Input & Output Representations
The type inference problem is modelled as a sequence-to-sequence task, tagging variable locations of interest in raw code snippets and letting the model generate token-based type predictions per tag.
We make use of our usage slices to accurately match objects with their occurrences in source code, annotating the variable’s declaration (or parameter declaration) as well as occurrences. This is then prefixed by a task description: “Infer types for JavaScript:”. Finally, the task is tranformed into its numerical representation using CodeT5’s tokenizer.
Training
For training and testing purposes, we make use of ManyTypes4TypeScript dataset. The test split comprises 662 055 TypeScript functions with a total of 8 696 679 type annotations, featuring 50 000 different types. After pre-processing and tokenization for the sequence-to-sequence task, we have 1 758 378 samples in the training set. We fine-tune CodeTIDAL5 for a total of 200k steps.
Integration in Joern
Joern has a modular design, with the core of it beginning at the language agnostic AST schema. The component responsible for parsing a program and abstracting the source code into this AST is the language frontend. Once the AST creation is complete, subsequent analysis is performed on the graph in what are called “passes”. For example, the control-flow (CFG) pass accepts the AST and thereafter the data-dependence (DDG) pass accepts the CFG, and so on and so forth until we have a complete analysis-ready CPG.
We package our model in a simple Python server allowing us to communicate with it directly over TCP. We name this component JoernTI, and how it integrates with Joern is shown below.

Evaluation
To evaluate CodeTIDAL5, we compare the type inference performance against related neural type inference models, as well as manually inspect an the results when run against some open-source projects from GitHub.
Type Inference Generalization
We compare our approach against the following models:
- LambdaNet: A robust baseline for neural type inference, whose dataset is commonly re-used in subsequent work.
- TypeBert: An early but successful approach to address the domain using LLMs and modelling the problem as natural langauge.
- GCBert-4TS: A GraphCodeBert base model fine-tuned on the ManyTypes4TypeScript dataset, currently leading the CodeXGLUE benchmark for type inference.
The two datasets used are the LambdaNet (LN) dataset and the ManyTypes4TypeScript (MT4TS) dataset. While we can use the MT4TS dataset as is, we make the following adjustments for the LN dataset:
First, we remove the non-expressive type annotations Function and void from the sample set. Secondly, we only consider variables with usages besides assignments.
Furthermore, we aim for a more challenging dataset, better reflecting real-world use cases of type inference where already annotated types are of no interest, or may not already be solved by simple type propagation. We mask all type annotations annotations during inference for TypeBert, GCBert-4TS and CodeTIDAL5. For this, we obfuscate all object instantiations where a type’s name can be derived from the new call, as well as manual type annotations.
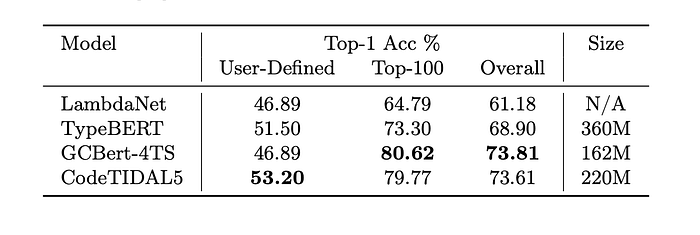
For evaluation on the LN dataset, for all approaches we perform greedy matching: Specifically, we infer the type of a variable at multiple locations where it is used in the source, instead of only, e.g., at instantiation, and choose the highest confidence match in order to evaluate a label against the ground truth for a variable.
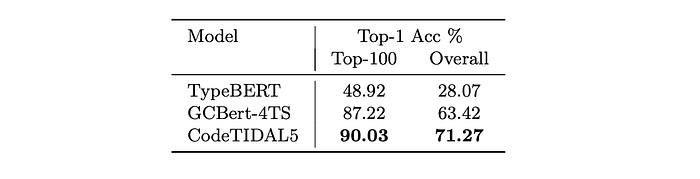
On MT4TS, we only consider exact matches per unique variable usage location. In accordance with previous work, we exclude labels with the ambiguous any tag, and consider UNK predictions as incorrect.
On the more diverse and larger ManyTypes4TypeScript dataset, our approach achieves an overall improvement of 7.85% in type prediction accuracy against the current best published model GCBert-4TS.
TypeBert’s comparatively low accuracy is probably explained by the reduced context size. Where GCBert-4TS and CodeTIDAL5 see a context window of 512 code tokens at a time, TypeBert is trained to only process inputs of 256 tokens.
Efficacy of JoernTI
This section investigates the integration of Joern and CodeTIDAL5 via the JoernTI server. All static analysis problems are analyzed as partial program analysis, i.e., no dependencies are retrieved and loaded into the analysis.
This downstream task illustrates a less resource intensive program analysis task, where CodeTIDAL5 compensates for the missing external type dependencies. All experiments were conducted on an M1 MacBook Pro (2020), 16 GB RAM.
We infer types on 10 open-source JavaScript repositories from GitHub and manually review the inferred results. We label the suggested types under the following four categories:
- Correct: The inferred type is an exact match with the actual type.
- Partial: The inferred type behaves similarly to the actual type or is its interface or supertype, e.g.
__ecma.Requestversus inferringNextApiRequest. - Useful: The actual type is not a defined type in the current context, but is plausible, e.g.
Object{name: String, pass: String, email: String}versus inferringUser. - Incorrect: The inferred type is completely incorrect.
The table below shows the result of the manual labelling task.
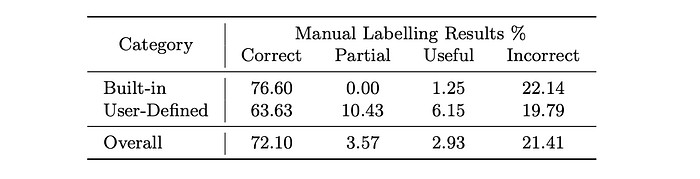
The result in the “Correct Overall” category alone seems to be consistent with the results from the MT4TS dataset. This confirms the generalization potential of CodeTIDAL5.
Case Study
Consider the following scenario: As security researchers, we are looking for potential database injections (CWE-943) in the context of AWS’ DynamoDB. This scenario is illustrated by our running example our Design section.
Knowing that the bodies of incoming events are a potentially attacker-controlled source, we develop the following Joern query:
def src = cpg.identifier
.typeFullName(".*(express.|NextApi|__ecma.)Request")
.inFieldAccess.code(".*\\.body\\..*")
def sink = cpg.identifier
.where(_.and(_.typeFullName(".*DocumentClient"),
_.argumentIndex(0)) // Receivers are at 0
).inCall.name("query")
sink.reachableBy(src)The query looks for a dataflow from a special element, in this case parameters tainted by an object of types __ecma.Request, __express.Request, or NextApiRequest, into database query logic. Without proper sanitization, this may lead to a NoSQL injection.
While JoernTI returned NextApiRequest for the parameter req, this code snippet alone is extremely low context and, with one or two minor changes to how the handler is defined, we find the inference returning __ecma.Request. With the context given, we cannot give much more ground truth outside of stating “this type is the request body for an HTTP handler”.
This trend extends to how we observe CodeTIDAL5 accuracy improve on larger procedures in general, especially if require statements are available. The additional context allows CodeTIDAL5 to infer types more accurate to the ground truth. On the other hand, when looking at low context or less common coding patterns, we see more incorrect inferences or hallucinations for types not present in the codebase at all.
Mitigating Errors & Hallucination
While the above is a promising contribution to finding more flows during taint analysis, the impact of the ~25–30% incorrect inferences for less common types may still be intolerable yet. Work towards filtering out these incorrect inferences may be necessary to further allow neural type inference adoption in sensitive production environments.
Can we detect invalid type inferences?
We allow the user to specify a TypeScript declaration file which our inference pass will check the suggested type against the variable’s usages. If the usages invoke methods contradictory to the type’s defined methods, we mark this as a type violation and skip the inference. While leading to a lower yield, this reduces the number of false inferences.
Example:
lib.es5.d.ts tells us String does not have a .body property, so req should not be a String (in most cases)
Do we infer everything?
No, as not everything has a usage (or needs it).
The user can specify the minimum number of usages a variable requires to be sent for inference. This increases the known context and may boost accuracy.
If, for example, a constructor is in the file, Joern’s type propagation would likely solve the missing type information for that variable.
Conclusion
We present and make available CodeTIDAL5, a neural type inference model based on CodeT5+ that uses source code context as well as precise slices to query variable types in JavaScript/TypeScript. Additionally, we demonstrated the plug-and-play capability of CodeTIDAL5 using JoernTI, a queryable server for remote type inference, available as an open-source extension to Joern.
We find that this model has great potential to improve downstream tasks such as source/sink tagging for taint analysis, receiver type information for call graph analysis, and improve the features available to code vectorization and mining tasks.
We would like to thank Kevin Jesse for help with the MT4TS dataset and models.
